


大模子一个 token 一个 token 生成,驱散太低怎么办?
微信 AI 联手清华大学,提议了一个新的解法:
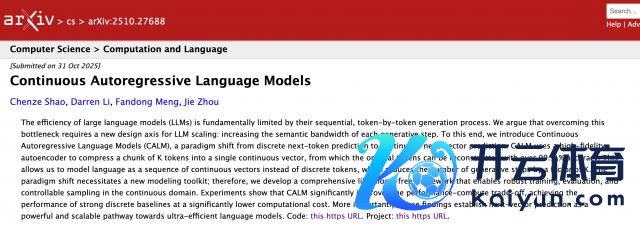
一个 token 能装下的信息太少,不如把它们打包成邻接向量,让大模子从量度下一个 token,转动为量度下一个向量。
筹谋团队给这种新范式取名CALM(邻接自追想言语模子)。
实验标明,将 K 个词元压缩成一个邻接向量,不错将言语模子建模为一系列邻接向量,生成才略减少至原本的 1/K。
这么一来,模子就能在均衡性能和野心资本时,终了更高的性价比。
有网友觉得,这种方法看上去越来越接近大脑践诺措置荆棘文的阵势。

还有网友提议,CALM 像是 DeepSeekOCR/Glyph 的改良版。

提高每个量度单位的语义带宽
筹谋东谈主员指出,量度下一个 token 的现存模子范式,一启动是因为基于字符级运行的模子野心量太大而被提议的。
也即是说,方法背后的要道想想是:提高每个文本单位的信息密度,概况镌汰序列长度并权臣提高模子驱散。
进一步挖掘骨子,不错总结出一条提高大模子生成驱散的灵验阶梯:捏续提高每个量度单位的语义带宽。
问题在于,若是想让一个 token 装更多的信息,就得把词表作念得超大,反而会让野心量和存储资本爆炸。
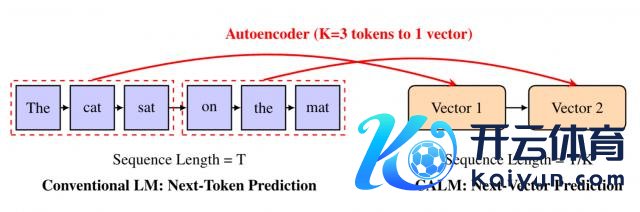
微信 AI 和清华大学团队想了个概念:把多个 token 打包成一个邻接向量,让模子每次措置一个向量,而不是一个 token。这么一来,比如一个序列的长度为 T,将 K 个 token 打包为 1 个向量,序列长度就会镌汰为 T/K。
他们想象了一个高保真自编码器,能将 K 个 token 压缩成一个邻接向量,并能以跨越99.9%的准确率从中重构原始 token。
邻接自追想言语模子
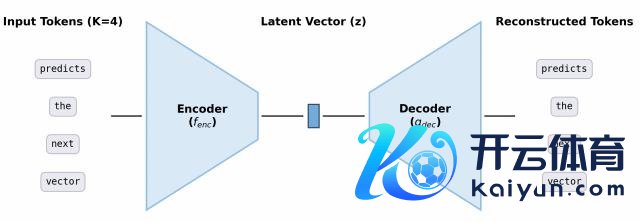
不外,从措置 token 向措置向量转动,还濒临着一个要紧挑战:
由于不存在有限词汇表,模子将无法借助措施的 softmax 层,对所有这个词可能驱散野心出明确的概率散播。
这也就意味着,需要为此征战全新的建模用具。
于是,筹谋团队提议了CALM——一套无缺的、无需依赖概率似然的框架。
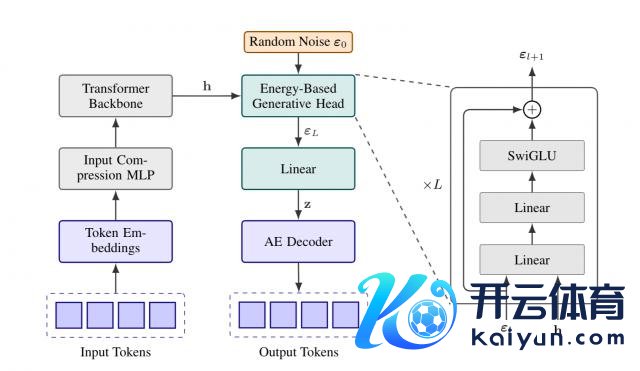
△CALM 框架无似然言语建模
试验方面,CALM 采用"能量亏蚀"来教模子学习邻接向量。
毋庸算概率,而是改用"能量分数"来判断模子生成的向量好不好。
具体来说,为了终了邻接向量生成,筹谋东谈主员采用轻量级生成头动作模子的中枢输出组件。该生成头以临了一个荫藏景色为条目,来生成输出向量。
同期,为幸免迭代式采样经由形成新的推理瓶颈,筹谋东谈主员引入了Energy Transformer。
Energy Transformer 专为邻接向量的高效单步生成想象,无需迭代,仅需 1 步野心即可输出邻接向量。
能量亏蚀是 CALM 试验 Energy Transformer 时用的亏蚀函数,不依赖概率野心,而是用"距离"和"各样性管理"两个维度判断向量质地——既让生成的向量逼近信得过值,又幸免模子只会生成一种向量。
无似然言语模子评估
不算概率了,困惑度(Perplexity)这个评估贪图也就不好用了。
为此,筹谋东谈主员提议了BrierLM,一种基于布里尔分数的新式言语模子评估贪图。
只需从模子中抽取样本,就能无偏地估算出 BrierLM 值。
实考据明,BrierLM 值和困惑度高度关系,能保证对模子才气的自制比拟。
无似然温度采样
当今流行的大言语模子是通过温度采样来终了可控生成的,但这一样依赖于概率散播。
CALM 提议了无似然温度采样,这一算法基于拒却采样,通过弯曲样本的继承概率来终了温度末端。

实验驱散:更具性价比
筹谋东谈主员通过实验考据,CALM 在均衡性能和野心资本时更有性价比。
在措施言语建模任务上,CALM-M(K=4,参数目 371M)在性能上与 Transformer-S(281M 参数)颠倒,但试验浮点运算数(FLOPs)减少了 44%,推理 FLOPs 减少了 34%。
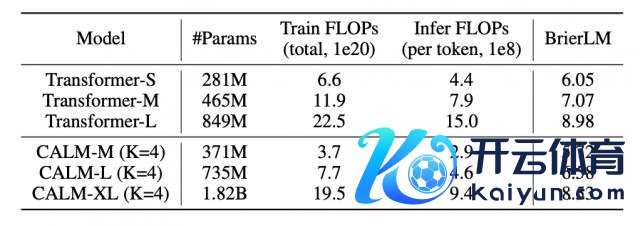
模子越大,CALM 的上风越澄澈。况兼跟着语义带宽 K 的增多,CALM 的性能 - 驱散比也会更优。
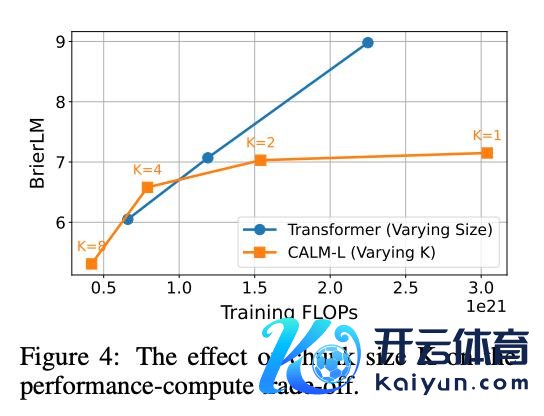
不外,筹谋东谈主员也提到,压缩的 token 数 K 太多时,反而会导致性能下落,可能需要更换更大的模子。
论文地址:
https://arxiv.org/abs/2510.27688
一键三连「点赞」「转发」「预防心」
迎接在褒贬区留住你的概念!
— 完 —
� � 年度科技风向标「2025 东谈主工智能年度榜单」评比报名火热进行中!咱们正在寻找 AI+ 时期领航者 点击了解笃定
❤️� � 企业、居品、东谈主物 3 大维度,共建树了 5 类奖项,迎接企业报名参与 � �
一键心扉 � � 点亮星标
科技前沿发达逐日见开yun体育网